二分归并排序

思路
计划以10W,50W样例来对两组算法进行测试。根据计算我们可以知道,冒泡有两层嵌套,需要$O(n^2)$时间;归并排序需要$O(n logn)$时间。
极简分析法:
1 | T(n) 拆分 n/2, 归并 n/2 ,一共是n/2 + n/2 = n |
一共有$\log(n)$层,故复杂度是 $O(n \log n)$
下面给出图示案例:
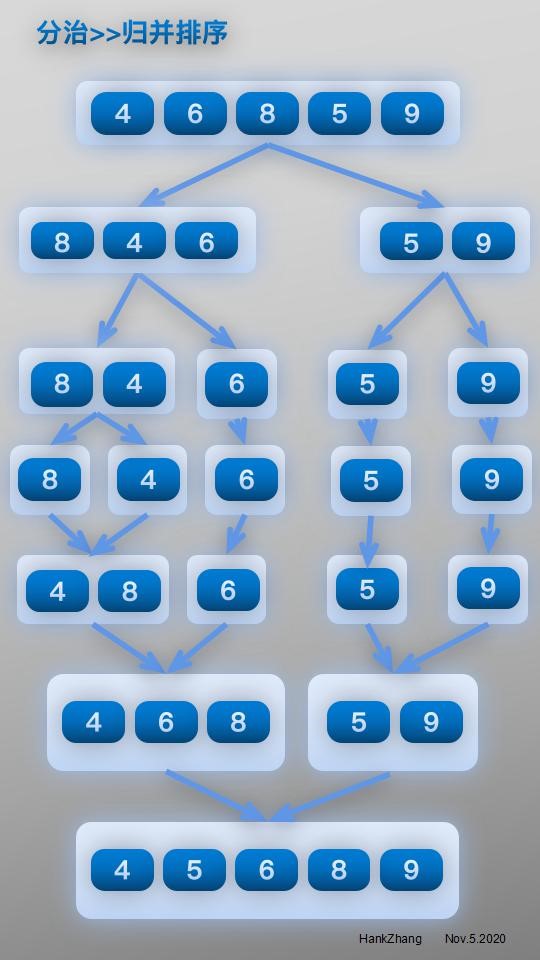
代码
数据生成
1 | //---------------------------------------------------- |
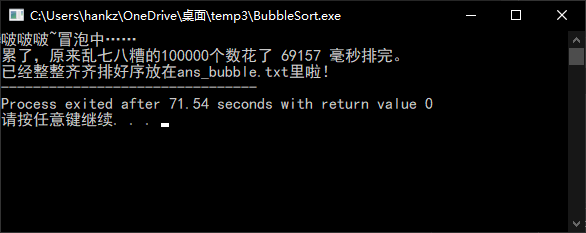
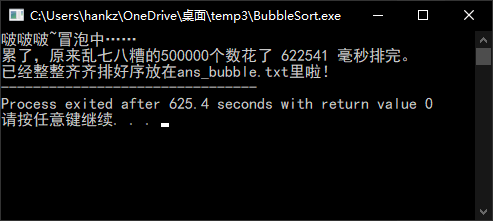
冒泡排序
1 | //---------------------------------------------------- |

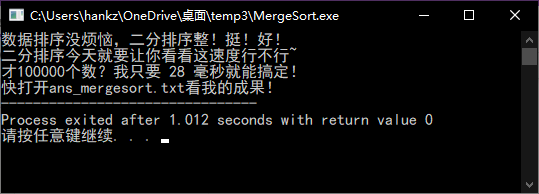
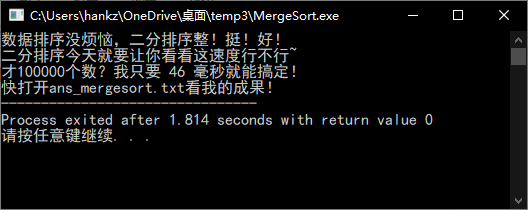
归并排序
1 | //---------------------------------------------------- |
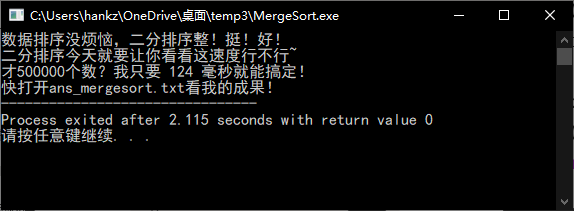
总结与心得
可以看到冒泡算法与归并排序在对于大数量级的数据的处理时间上差别巨大。对于10W的规模,冒泡的20余秒还在可以接受的范围内,但当仅仅扩大了5倍,规模来到50W的时候,冒泡排序需要的时间竟达到惊人的10分钟。而归并算法依旧以毫秒的时间计量完成了排序。
主观感知上,$n^2$ 与 $n \log n$ 差别好像不是很大,但实验结果告诉我们:对于大的数据规模,任何微小的不同都会引起近乎不啻天渊的差别。
不仅仅去依靠感知,而动手去做;不要小看些许差别,而精细入微。这个道理不仅存在于算法这项自科之中,也会成为我们学习处事的启示……
评论
评论插件加载失败
正在加载评论插件