1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
|
#include <iostream>
#include <cstdlib>
#include <ctime>
using namespace std;
int scan(int *data,int n)
{
FILE *fp=fopen("data.txt","r");
for(int i=0;i<n;i++)
fscanf(fp,"%d",&data[i]);
return 0;
}
int print(int *data,int n)
{
FILE *fp=fopen("ans_mergesort.txt","w");
for(int i=0;i<n;i++)
fprintf(fp,"%d\n",data[i]);
return 0;
}
void merge(int arr[], int low, int mid, int high){
int i, k;
int *tmp = (int *)malloc((high-low+1)*sizeof(int));
int left_low = low;
int left_high = mid;
int right_low = mid + 1;
int right_high = high;
for(k=0; left_low<=left_high && right_low<=right_high; k++){
if(arr[left_low]<=arr[right_low]){
tmp[k] = arr[left_low++];
}else{
tmp[k] = arr[right_low++];
}
}
if(left_low <= left_high){
for(i=left_low;i<=left_high;i++)
tmp[k++] = arr[i];
}
if(right_low <= right_high){
for(i=right_low; i<=right_high; i++)
tmp[k++] = arr[i];
}
for(i=0; i<high-low+1; i++)
arr[low+i] = tmp[i];
free(tmp);
return;
}
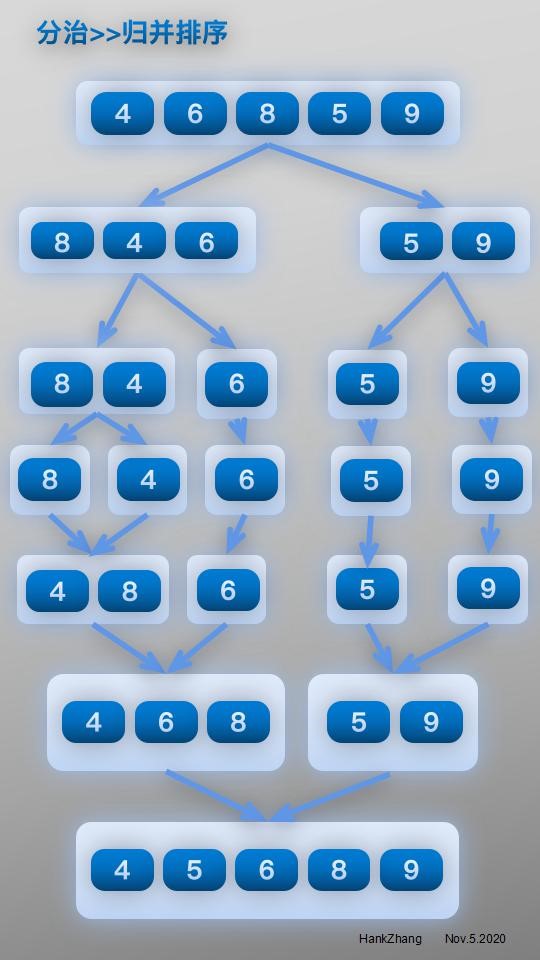
void merge_sort(int arr[], unsigned int first, unsigned int last){
int mid = 0;
if(first<last){
mid = (first+last)/2;
merge_sort(arr, first, mid);
merge_sort(arr, mid+1,last);
merge(arr,first,mid,last);
}
return;
}
int main()
{
int n;
n=100000;
int data[n];
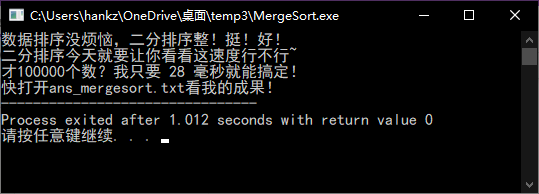
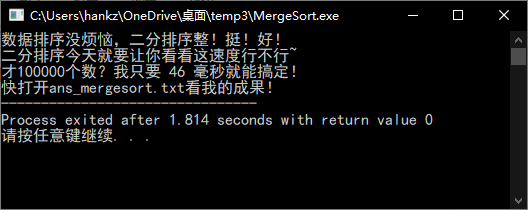
printf("数据排序没烦恼,二分排序整!挺!好!\n二分排序今天就要让你看看这速度行不行~\n");
scan(data,n);
merge_sort(data,0,n);
printf("才%d个数?就这?快打开ans_mergesort.txt看我的成果!",n);
print(data,n);
return 0;
}
|